The SciKnowMine Triage Application
We present here a user manual for running and maintaining a web-based system for peforming document triage given a corpus of PDF files. We will describe processes for installation, execution and maintenance of the system.
- Installation Manual
- System Organization
- Command Line - Set up
- Command Line - Working with Data
- Command Line - Reporting Functions
- Command Line - Deleting Data
- Command Line - Machine Learning
- Command Line Tools - Running Experiments
- Web Application - Running the System
- Web Application - Extracting text using LAPDF-Text
- Web Application - Performing the triage task
- Web Application - The Base Digital Library
9. Web Application - Running the System
The command line system provides preliminary data management capabilities for SciKnowMine but the web application brings together the elements as a whole.
See the SciKnowMine Web Application github page for instructions on how to install and run the system from source (Recommended).
From the top page, click on the Run the system button to start SciKnowMine.
The SciKnowMine Triage system will start with a dashboard, shown below.
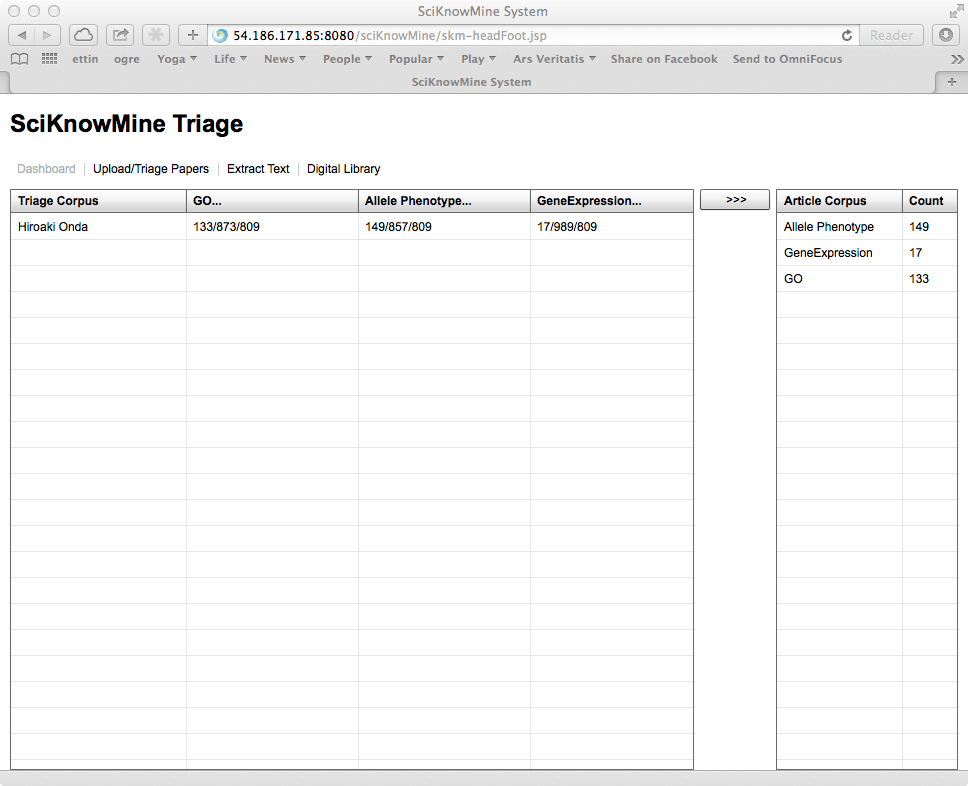
The panel on the left shows TriageCorpus objects (collections to be sorted into
categories, in this case showing the work of one curator: Hiroaki Onda). The list on the
right shows the category that they are being assigned to. This is the base function of the
system. Clicking the >>> button transfers newly assigned papers across all the triage
corpora to their assigned categories.
The links at the top of the page show the different modules that form the main functionality of the system.
- Upload/Triage Papers - provides the primary function of the system
- Extract text - systems for accurately extracting text from PDF files.
- Digital library - general bibliographic management once the papers have been triaged.
We will focus on the text extraction first, followed by the triage task followed by the more general functionality of the digital library.