The SciKnowMine Triage Application
We present here a user manual for running and maintaining a web-based system for peforming document triage given a corpus of PDF files. We will describe processes for installation, execution and maintenance of the system.
- Installation Manual
- System Organization
- Command Line - Set up
- Command Line - Working with Data
- Command Line - Reporting Functions
- Command Line - Deleting Data
- Command Line - Machine Learning
- Command Line Tools - Running Experiments
- Web Application - Running the System
- Web Application - Extracting text using LAPDF-Text
- Web Application - Performing the triage task
- Web Application - The Base Digital Library
10. Web Application - Extracting text using LAPDF-Text
We have described the underlying methodology of our PDF-text extraction system in a publication found here: http://www.scfbm.org/content/7/1/7/abstract
The basic premise of our work is that we want to obtain the most accurate text from PDF files as possible. PDFs are the 'lowest common denominator' format for scientific papers, they are stored and used by scientists and are very familiar for end users, but they are somewhat cumbersome to use. In particular, standard PDF processing systems may make mistakes reconstructing precise narrative flow across pages and blocks. The LAPDF-Text library (standing for Layout-Aware PDF text extraction) detects blocks of text using spatial indexing and then applies rules developed for the formatting layout of each 'epoch' of a given journal to reconstruct the text as accurately as possible. Even then, this approach does not work 100% of the time and we are working to improve it.
The basic screenshot of this module can be seen below.
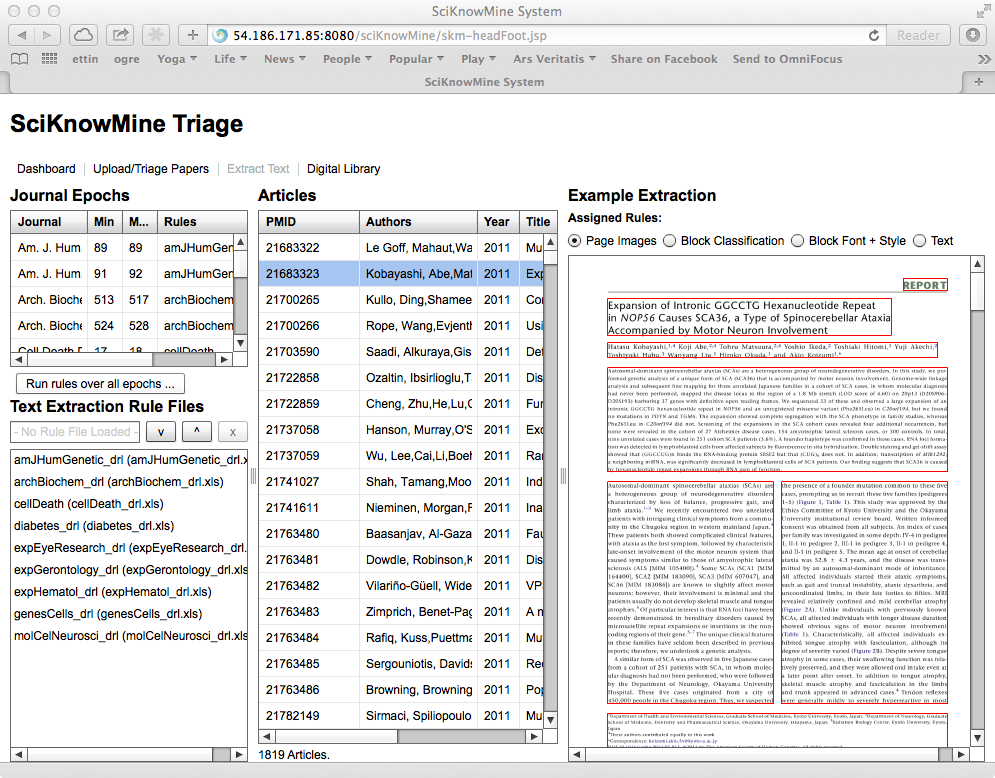
This shows a library of 1819 articles with one selected (Kobayashi et al. 2011), where the text blocks for the paper are shown. Clicking on the 'Block Classification' button on the Panel on the right hand side reveals how the system sees the structure of the paper.
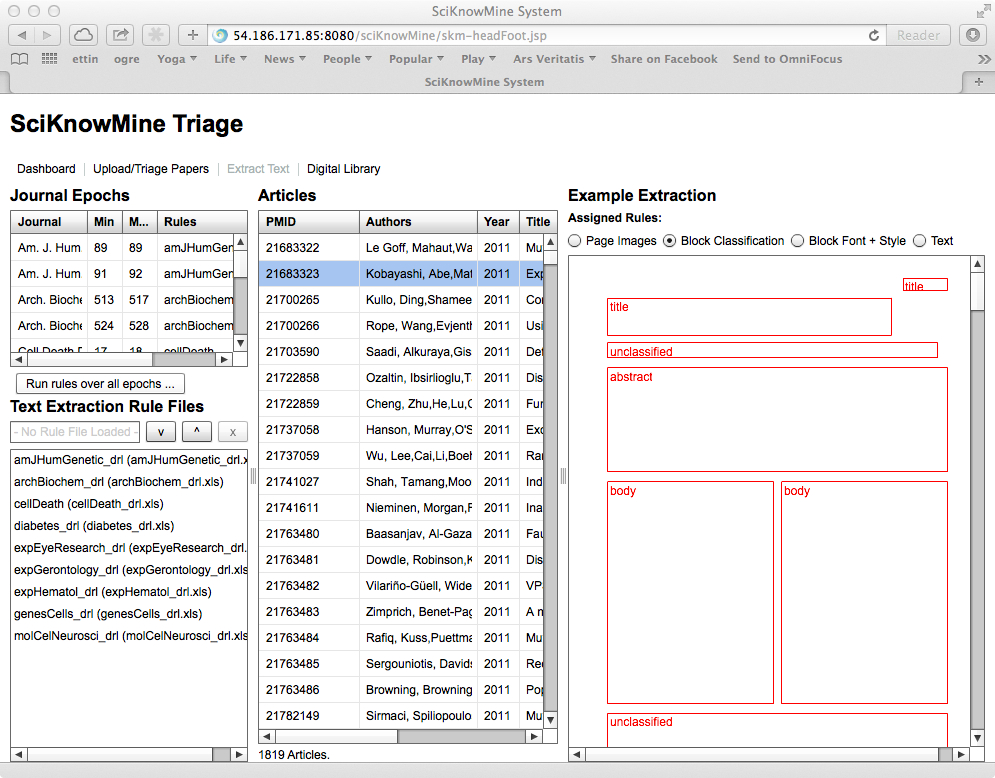
The key to this work is developing effective rule files for the extraction. These are shown
in the panel to the bottom left of the system. By clicking on the v button, you may
download a rule file (which are just Excel spreadsheets, shown below).
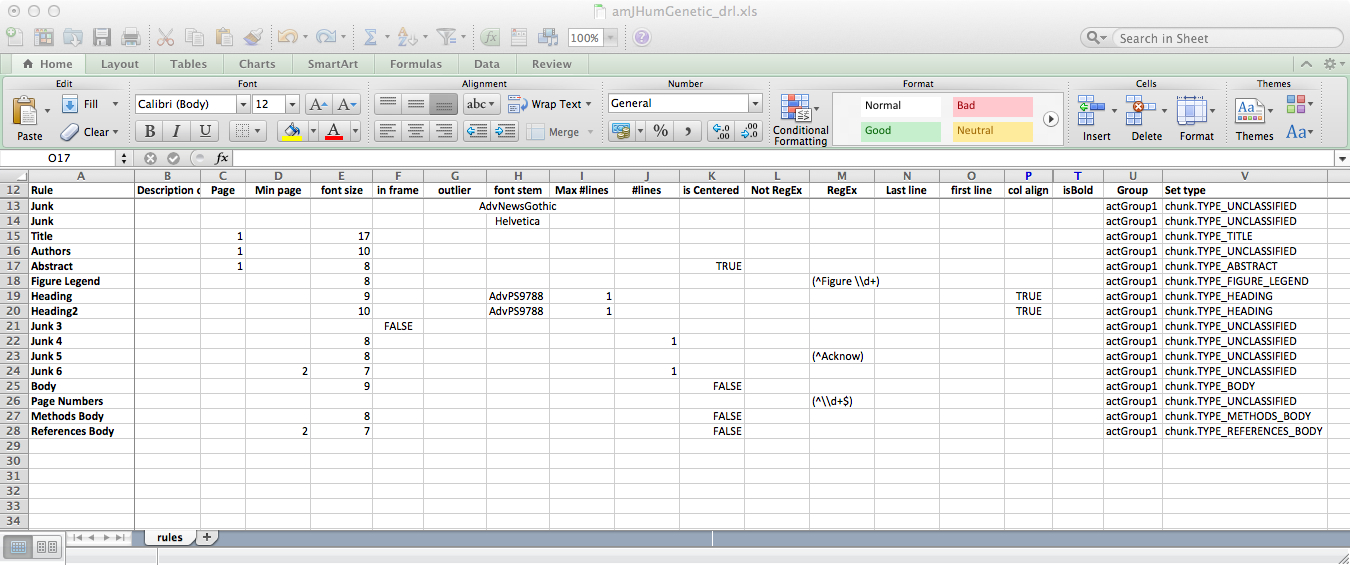
The system applies each rule in the order listed in the spreadsheet (using the DROOLS formalism from JBoss). If all conditions for a given row are met, the type of the text block (or 'chunk') is set to the value shown in the far right column of the spreadsheet. The user may then upload the file and then drag-and-drop the rule file entry from the list to the panel showing the file on the right. The system will then apply these rules and update the panel accordingly. It is therefore relatively easy to tune a rule file's logic and improve the text extraction accuracy.
We must applying these rule files to documents en-masse. You may do this by dragging and dropping the rule file to the list of sorted journal epochs shown at the top left. This assigns the rule file to that epoch. You may then execute the rule file over the entire epoch by clicking the button in that panel.